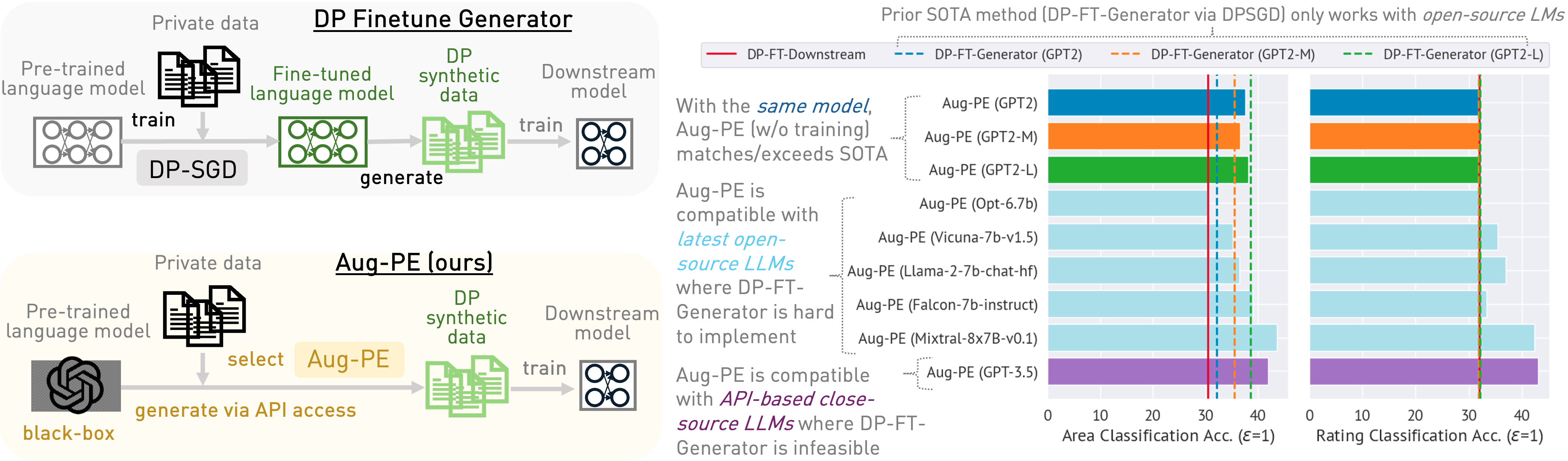
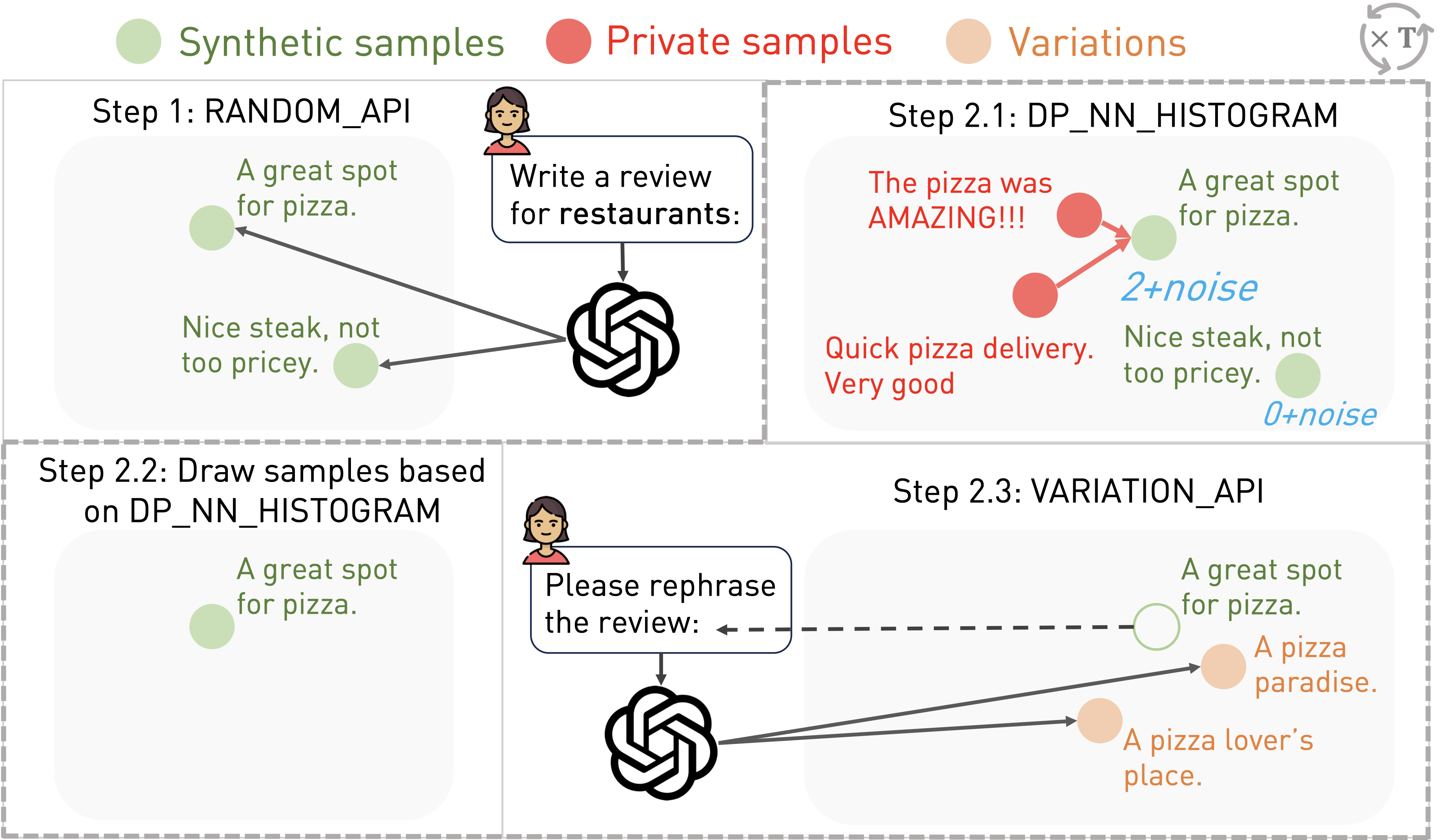
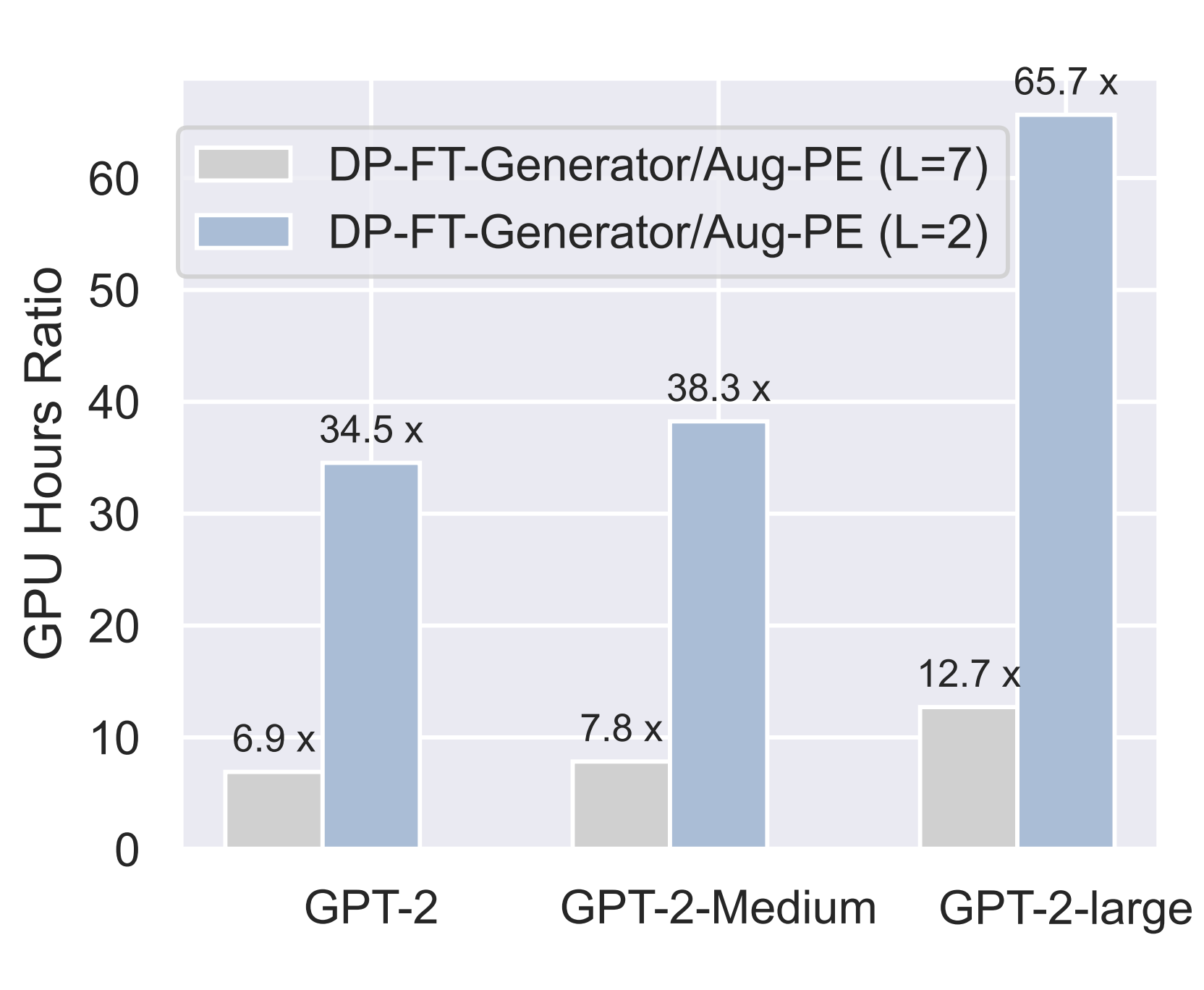
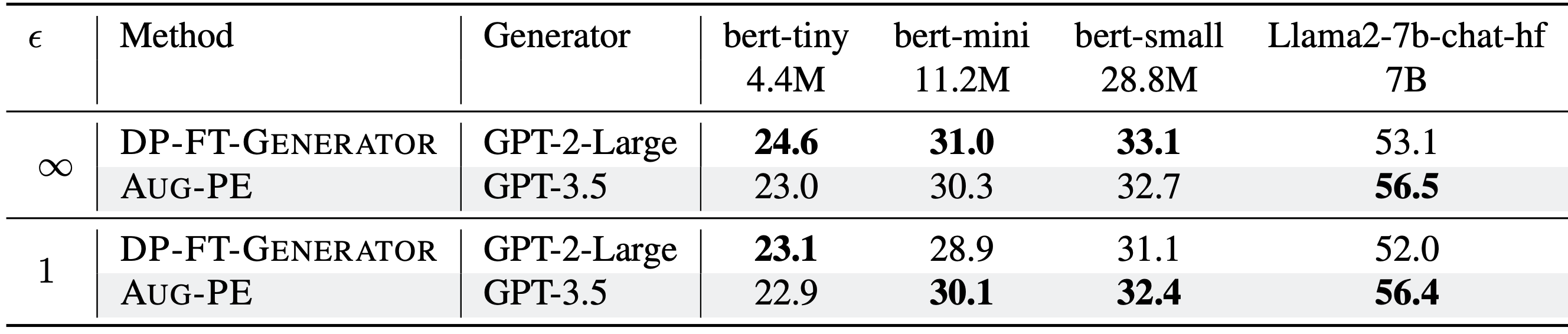
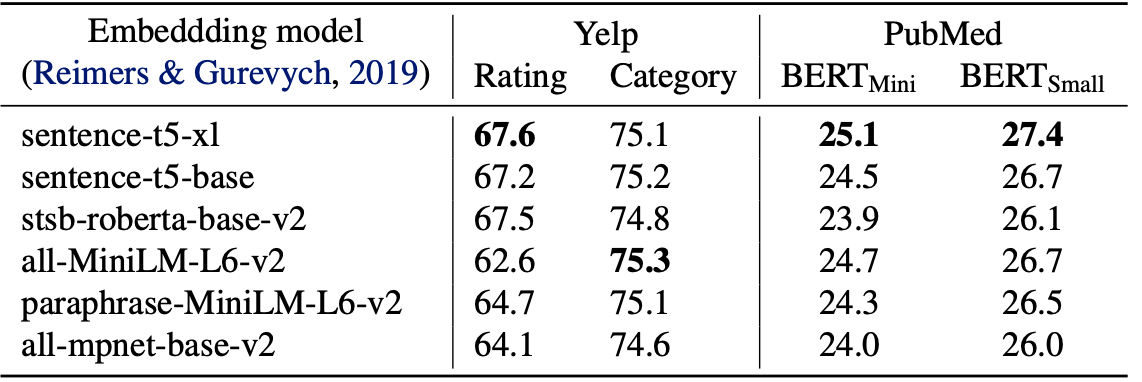
We compare Aug-PE to two SOTA methods involving DP finetuning:
- DP-FT-Generator (Yue et al, 2023): finetuning generator (e.g., GPT-2) with DP-SGD
(note that we cannot DP finetune closed-source GPT-3.5) and using synthetic texts to finetune downstream model with non-private SGD.
- DP-FT-Downstream (Li et al, 2022, Yu et al, 2022): finetuning downstream model on real data with DP-SGD.
This baseline is not a competitor to our method, since our goal is to generate DP synthetic data and not merely train a downstream model.
With the same generator, Aug-PE is on par with DP finetuning in some cases
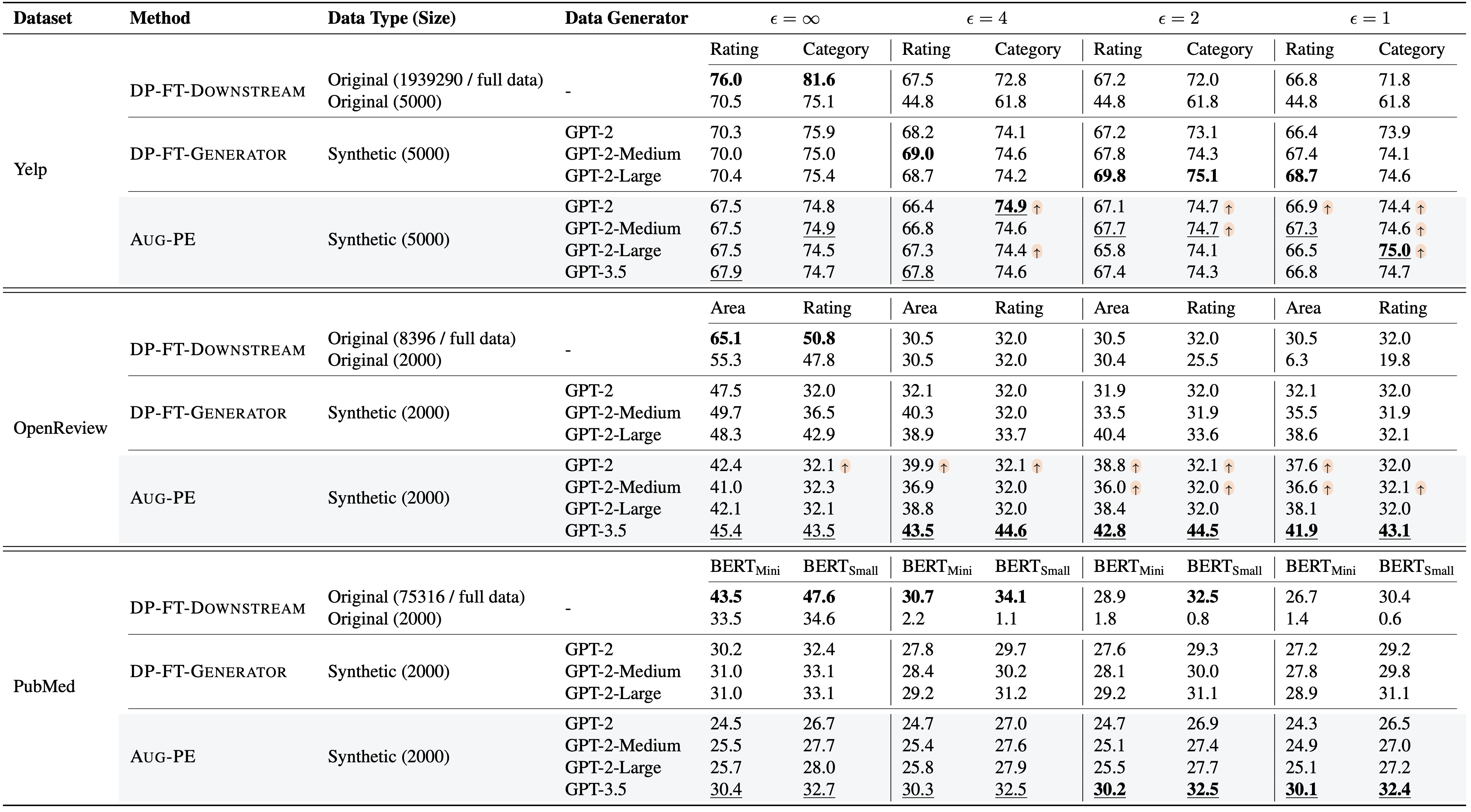
We evaluate the downstream model accuracy of Aug-PE and two baselines along different data generators.
The highest accuracy across all methods (obtained by Aug-PE) is bolded (underlined).
- Compared to DP-FT-Generator, in some cases, downstream accuracy of Aug-PE is higher (↑) under the same size of GPT2-series data generator.
- Compared to traditional method DP-FT-Downstream, Aug-PE can also obtain higher accuracy under DP.
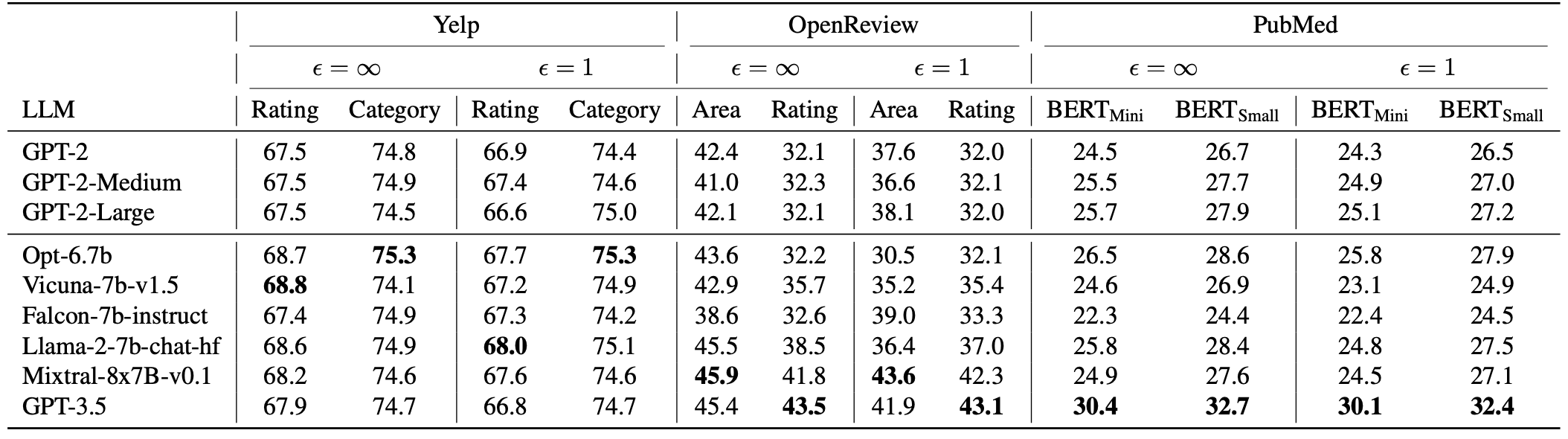
Aug-PE is compatible with closed-source LLMs for improved utility, where DP finetuning is infeasible
Leveraging the inherent knowledge within stronger LLM, GPT-3.5, Aug-PE can achieve higher accuracy,
especially on challenging datasets OpenReview and PubMed,
outperforming DP-FT-Generator by a notable margin.
Many powerful LLMs such as
GPT-4, Claude, and Bard are only accessible through inference APIs.
DP finetuning them is not feasible. Although standard finetuning APIs are provided for some of the models,
DP finetuning requires a special
implementation (i.e., DP-SGD) and no model provides this custom API to date.
Aug-PE is compatible with open-source LLMs, where DP finetuning is hard to implement
Using powerful open-source LLMs, such as Mixture-of-Expert Mixtral-8x7B-v0.1, as data generator, leads to improved downstream accuracy for Aug-PE on three datasets.
Finetuning those open-source LLMs with
DP is resource-intensive and non-trivial to implement due
to the need of calculating per-sample gradient in DP-SGD. The state-of-the-art DP
synthetic text approaches are unfortunately still based on
GPT-2 (Yue et al, 2023).